タグ: ゲーム理論
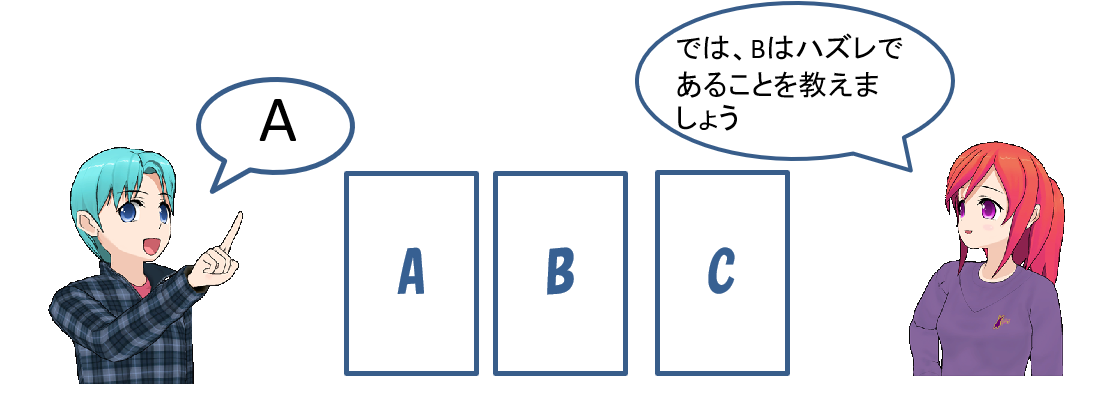
モンティ・ホール問題の分かりやすい説明:「直感的説明」は間違ってることが多い
※本記事に対してメールを頂き、それを受けて少し書き直しました。ありがとうございました。(2024/03/16)…




ビジュアル「ゲーム理論」 (日経文庫)
日経文庫「ビジュアル ゲーム理論」を出版しました(2019年)。これはロングセラーになった「図解雑学ゲーム理論…

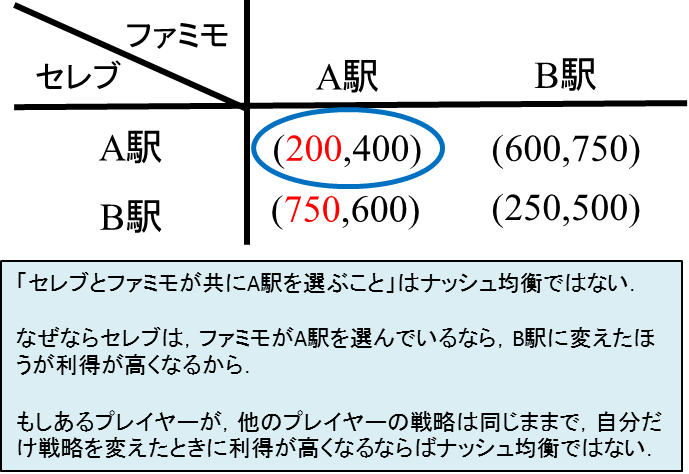
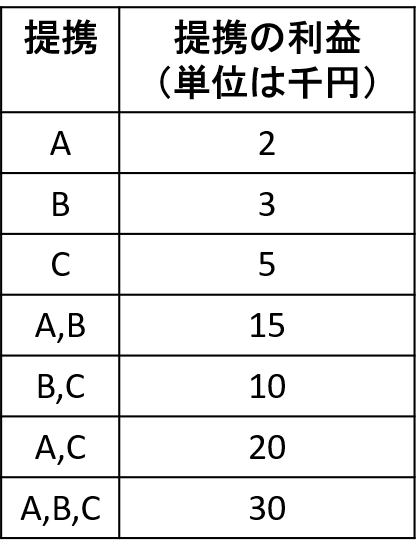

※本記事に対してメールを頂き、それを受けて少し書き直しました。ありがとうございました。(2024/03/16)…
日経文庫「ビジュアル ゲーム理論」を出版しました(2019年)。これはロングセラーになった「図解雑学ゲーム理論…